I read some news a while ago which inspired me to write this post.
http://www.darkreading.com/deactivated-user-accounts-die-hard/d/d-id/1251034
http://www.securityweek.com/windows-authentication-protocol-allows-deactivated-user-accounts-live-report
It’s about a flaw in Kerberos and how Windows handles user account revocation. The flaw makes is possible for a user to have access to systems up to 10 hours after the account has been, disabled, deleted or locked out.
This is no direct news, and I believe that the 10 hours could be much greater if you look outside Kerberos and take the replication convergence in consideration.
When a user is deleted, disabled or locked out this has to be replicated to all replicas in the domain, meaning all the DCs needs to be updated with this information.
If you have a domain with multiple sites and have configured special replication intervals and scheduling, it could take a while before the whole domain is up to date.
If we look at the replication we have four basic things to start with:
- Intra-Site replication – the replication between DCs within a site.
- Inter-Site replicaition – the replication between sites.
- Urgent replication – when it needs to go fast.
- Change notification between sites – speed up Inter-Site replication.
Intra-Site replication:
If you have multiple DCs in a site they will form a bidirectional replication ring between each other based on its own information about the Sites and Services configuration. The Knowledge Consistency Checker (KCC) is the one responsible for this.
When a change in a Naming Context (in this case the DNC) is done it will send a change notification to its replication partner about the update.
The way this works on 2003 DCs and later versions:
The source DC where the change has been made wait 15 seconds and then send an update notification to its closest replication partner. If it has multiple partners it waits three seconds before sending the change to each partner to minimize the risk of getting answers from all of them at the same time.
The destination DCs will respond with a directory update request and the source domain controller will reply with a replication operation.
Inter-Site replication:
Inter-Site replication is when you have DCs placed in different sites. The KCC with the ISTG role generates a replication topology between sites and assigns one DC in its own site to be a bridgehead server. The bridgehead server is the one responsible for replicating between sites. The difference here is that they don’t send the change notification, instead a DC request changes from its bridgehead replication partners at a specific interval defined in the site link.
The default value of replication interval in the site links is 180 minutes and can be changed to the lowest of 15 minutes. It also has the ability to be scheduled to only replicate at a specific time of the day e.g. at night when no one is working.
Urgent replication:
Urgent replication is used when a change needs to go out immediately and send the update notification without waiting 15 + 3 seconds within a site.
The events urgent replication triggers on:
- Account lockout (performed by DCs)
- Changing the account lockout policy
- Changing the domain password policy
- Changing a Local Security Authority (LSA) secret, which is a secure form in which private data is stored by the LSA (for example, the password for a trust relationship)
- Changing the password on a domain controller computer account
- Changing the relative identifier (known as a “RID”) master role owner, which is the single domain controller in a domain that assigns relative identifiers to all domain controllers in that domain
Default this only happens between DCs within its own site. The replication interval on the site links is still honored. Here is a topology example with the minimum replication interval of 15 minutes between sites:
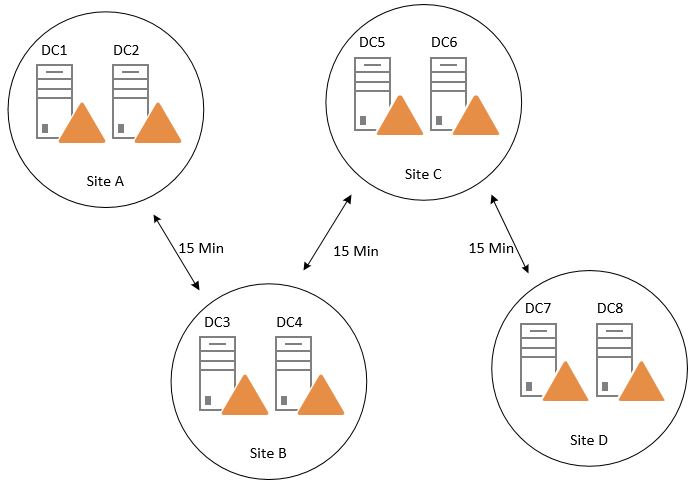
If a user account is disabled on DC1 it will send a change notification to DC2, the DC2 sends an update request and replicate the changes. DC3 follows the replication schedule that is set to 15 minutes and sends an update request to DC2. After the changes has been replicated it notifies DC4 that it has updates. And this will continue until DC8 has replicated and it could take up to 46 minutes. Urgent replication only helps us with the account lockout part, but still only within its own site.
Meanwhile the user can target to logon against DC8 and get service tickets to access resources as usual.
Inter-site change notifications:
With change notification between sites activated on the site links, the Inter-Site replication behavior is changed to act the same way as Intra-Site replication. The DC sends a change notification to its replication partner at the other sites with the 15 + 3 Sec schedule, and the inter-site replication intervals is ignored. This speeds up the replication convergence pretty good.
This requires good links between the sites, but now a days this isn’t a big problem for the most of the Active Directory environments. The replication between sites still also uses compression to manage low-speed links (you could turn that of if you would like to do that).
By enabling this you also get better protection against write conflicts since the replication occurs much faster and you decrease the convergence. If a lot of changes is made it doesn’t either gets queued up as when they have to obey the inter-site replication interval.
This can be enabled in the ADSI Edit snap-in:
- Open ADSI Edit and connect to the Configuration NC.
- Navigate to the SitesContainer – Inter-SiteTransportContainer – IP Inter-SiteTransport.
- Click properties on the site links.
- In the Option Attribute change the value to 1 (5 if you want to disable compression).
With this enabled I will have an example of a replication topology that I personally like very much. The hub and spokes topology:
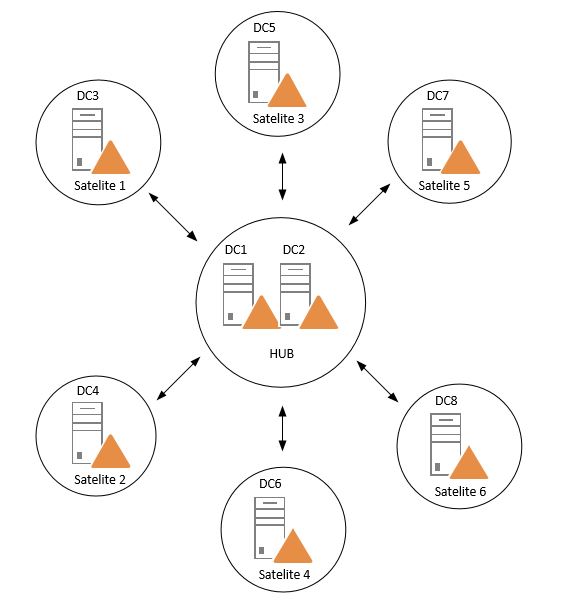
This is a really simple topology to overview and troubleshoot and it is scalable. By having a hub site and preferably where all the changes is made (and holds FSMO roles and so on), it gets replicated out fast in the domain to all satellite sites with Inter-Site change notification enabled.
In Windows Server 2008R2 they added load-balancing functionality for the Bridgehead server selection which makes it perfect for the DCs in the Hub site to evenly distribute the workload between each other to all the satellite sites.
With this design we are not talking about days or hours, the convergence could be down to under a minute.
Another example with Kerberos and replication convergence:
The problem with the replication interval has other side effects as well. For example when you remove a user from a Security Group with the purpose of revoking access to a folder, application or system.
If we look at how Kerberos ticket exchange occurs:
Microsoft has good documentation of their Kerberos implementation and this is a high level description taken from: http://technet.microsoft.com/en-us/library/cc772815(v=ws.10).aspx#w2k3tr_kerb_how_pzvx
The Authentication Service Exchange
1. Kerberos authentication service request (KRB_AS_REQ)
The client contacts the Key Distribution Center’s authentication service for a short-lived ticket (a message containing the client’s identity and—for Windows clients—SIDs) called a ticket-granting ticket (TGT). This happens at logon.
2. Kerberos authentication service response (KRB_AS_REP)
The authentication service (AS) constructs the TGT and creates a session key the client can use to encrypt communication with the ticket-granting service (TGS). The TGT has a limited lifetime. At the point that the client has received the TGT, the client has not been granted access to any resources, even to resources on the local computer.
Why use a TGT? Could the AS simply issue a ticket for the target server? Yes, but if the AS issued tickets directly, the user would have to enter a password for every new server/service connection. Issuing a TGT with a short lifespan (typically 10 hours) gives the user a valid ticket for the ticket-granting service, which in turn issues target-server tickets. The TGT’s main benefit is that the user only has to enter a password once, at logon.
The Ticket-Granting Service Exchange
3. Kerberos ticket-granting service request (KRB_TGS_REQ)
The client wants access to local and network resources. To gain access, the client sends a request to the TGS for a ticket for the local computer or some network server or service. This ticket is referred to as the service ticket or session ticket. To get the ticket, the client presents the TGT, an authenticator, and the name of the target server (the Server Principal Name or SPN).
4. Kerberos ticket-granting service response (KRB_TGS_REP)
The TGS examines the TGT and the authenticator. If these are acceptable, the TGS creates a service ticket. The client’s identity is taken from the TGT and copied to the service ticket. Then the ticket is sent to the client.
(Note! The TGS cannot determine if the user will be able to get access to the target server. It simply returns a valid ticket. Authentication does not imply authorization)
The Client/Server Exchange
5. Kerberos application server request (KRB_AP_REQ)
After the client has the service ticket, the client sends the ticket and a new authenticator to the target server, requesting access. The server will decrypt the ticket, validate the authenticator, and for Windows services, create an access token for the user based on the SIDs in the ticket.
6. Kerberos application server response (optional) (KRB_AP_REP)
Optionally, the client might request that the target server verify its own identity. This is called mutual authentication. If mutual authentication is requested, the target server will take the client computer’s timestamp from the authenticator, encrypt it with the session key the TGS provided for client-target server messages, and send it to the client.
Since the SIDs is in the tickets and the server actually never talks to the DC/KDC and verify anything (it trusts the KDC and the Service Ticket it generated to the client), the user will have the access specified when the ticket was created and keep it during the ticket lifetime. If a user is removed from a security group, it has to replicate to all DCs and the tickets needs to be renewed.
Could the “Good Standing” help us?
The Check Account Policy for Every Session Ticket Request is default enabled. If the TGT is older than 20 minutes when doing a Service Ticket Request the KDC is forced to verify if the account still is in “good standing”. It checks if the account has been disable, locked out, expired or the time is within logon hours. If any of these is true it will enforce revocation.
http://msdn.microsoft.com/en-us/library/cc233947.aspx
This doesn’t help with the case of removing Security Group membership nor replication convergence. It helps a little with generating new service tickets when the user has been disabled, deleted, locked out.
Summary:
These flaws is not new and it requires a good design when building your infrastructure and identity management. There is a lot of things to consider and evaluate to find an acceptable level and this is a few examples.
One other last example is the revocation of certificates when you store the CRLs in Active Directory, it also needs to bee replicated, and that should be handled in Urgent Replication, but it isn’t.
Depending on your site configuration, replication convergence and the Kerberos tickets it could take several hours and in worst case days until the account is definitely deleted/disabled in the domain.
Kerberos has been around for a long time counted in IT years and isn’t perfect and a replacement is welcome, but I think it will take a while before Kerberos is just a memory.
And one last thing that I want to mention, but can’t recommend (but its fun). If you have a superfast infrastructure from network and server capacity you could also change the 15 + 3 second notification rule to 0 by editing the registry:
Path: HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\NTDS\Parameters
Key: Replicator notify pause after modify (secs)
Value: REG_DWORD
Path: HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\NTDS\Parameters
Key: Replicator notify pause between DSAs (secs)
Value: REG_DWORD
That’s pretty much how fast it can get in a Multimaster replication environment. But you still have the Kerberos problems…